How to Verify CrowdStrike Is Running on Every Cloud Workload
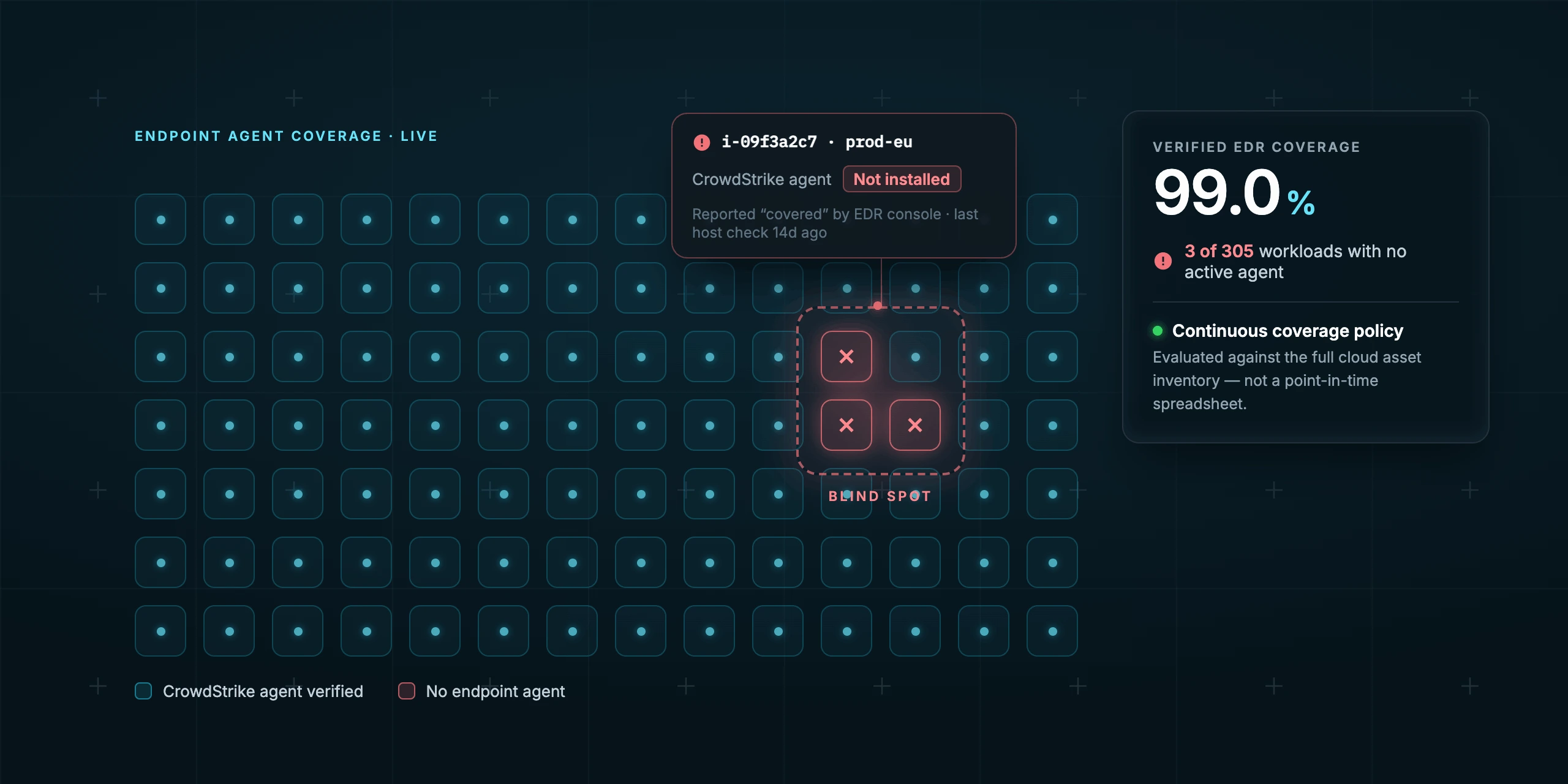
Most cloud security and EDR tools can't actually confirm that CrowdStrike is installed and running on every workload you own. Posture tools watch your cloud configuration. CrowdStrike watches the hosts it's already on. Neither reliably tells you where your agent is missing, so teams fall back to one-off scripts and spreadsheets that go stale the moment infrastructure changes. The durable fix is to treat agent coverage as a continuous policy that reconciles your full cloud asset inventory against live agent status.
Here's the gap, why it exists, and what closing it looks like in practice.
The question that started this
One of our customers came to us after an incident investigation with a simple, uncomfortable question:
"Can you check if CrowdStrike is actually running on every production workload?"
It wasn't an abstract worry. They'd just worked an incident where a compromised instance turned out to have no endpoint agent on it at all. Nobody knew the gap existed until they were already deep in the logs, reconstructing what happened. The assumption ("CrowdStrike is everywhere, that's the standard image") had quietly drifted out of alignment with reality, and the first time anyone noticed was during the worst possible moment to notice.
If you run security or cloud ops at any scale, you already know this feeling. You believe coverage is complete. You can't prove it on demand. And the gap between those two states is exactly where incidents hide.
Why no single tool owns this check
It seems like the kind of thing one of your existing tools should just answer. In practice, the responsibility falls into a seam between two categories that each see only half the picture.
Cloud posture tools (CSPM/CNAPP) look at configuration, not agent presence. Their job is the cloud control plane: open storage buckets, over-permissioned IAM roles, missing encryption, public exposure. They're excellent at "is this resource misconfigured." They are not built to look inside a workload and confirm that a specific third-party binary like the Falcon sensor is installed, running, and current. Some platforms can map the coverage of their own runtime sensor, but that doesn't tell you anything about the EDR you actually standardized on.
CrowdStrike sees the hosts it's already on, which is the heart of the problem. Falcon's console and APIs can show you inactive sensors, sensors in reduced-functionality mode, and stale check-ins. But a tool that lives on endpoints is structurally weak at reporting on endpoints where it was never deployed. If a workload spun up from an image without the sensor, or a team launched instances outside the golden pipeline, that host may simply never appear in the agent's view. You can't get an accurate "where am I missing?" answer from the thing that's missing.
The only system that actually knows every workload that exists is your cloud asset inventory: the control-plane truth across every account, region, and service. The check everyone wants is really a reconciliation. Take the complete list of workloads that should be protected, and subtract the list of workloads where the agent is verifiably healthy. What's left is your real coverage gap. No off-the-shelf product owns that join, because it spans two tools that don't talk to each other.
How most teams answer it today (and why it doesn't survive an audit)
Because nothing does it natively, this becomes a scripting project. The usual playbook:
- Pull the full host/instance list from each cloud account via API or CLI.
- Pull the active-sensor list from the CrowdStrike API.
- Diff the two in a notebook or spreadsheet, wrestle with naming and ID mismatches, and try to figure out which of the unmatched hosts are actually production versus ephemeral test boxes.
- Repeat the whole thing the next time someone asks.
It works exactly once. The output is a point-in-time snapshot with a shelf life measured in hours, because your cloud changes constantly. A manually maintained list of which workloads have a running sensor isn't a control; it's a screenshot of the past. When an auditor asks you to demonstrate continuous endpoint coverage across the last quarter, or when leadership asks "are we sure it won't happen again," a stale export doesn't answer the question. And rebuilding the script every cycle is precisely the kind of multi-week, multi-person effort that quietly eats your security team's capacity.
A better approach: make coverage a policy, not a project
So we built it as a policy.
In imPAC, the customer defined a custom check that evaluates CrowdStrike agent status across their entire cloud estate and flags any workload where the sensor is missing, inactive, or out of date, measured against the complete asset inventory rather than just the hosts CrowdStrike already knows about. They went from "we think CrowdStrike is everywhere" to "we can prove it, continuously, across every account" in about fifteen minutes.
The difference isn't speed for its own sake. It's that the answer is now:
Continuous, not point-in-time. The policy re-evaluates as infrastructure changes, so a workload that launches without the agent surfaces on its own instead of waiting for an incident to expose it.
Scoped to what matters. Coverage can be checked against production, Tier-1, or assets tagged with sensitive data, so you're not chasing alerts on dead test boxes.
Audit-ready by default. Because the history is captured over time, "show me endpoint coverage across Q2" is a pull, not a project.
The same model turns the incident-response question around, too. Instead of discovering a coverage gap during an investigation, the gap is already a tracked finding with an owner.
The bigger idea: if you can describe the check, you can build it
This is the part most people don't realize about imPAC. The policies aren't locked to a vendor's predefined list of checks. CrowdStrike coverage is one example, but the engine is general. If you can describe the check, you can build it, with no code:
- Backup and snapshot validation for critical databases and volumes
- Tagging standards enforced across every account
- Encryption requirements scoped to specific data classifications (e.g., anything tagged PII must use a rotated key)
- Replication and resiliency controls for Tier-1 workloads
- Any "we always assumed this was true, but can't prove it" assumption your team is carrying
These are exactly the infrastructure questions that don't fit neatly inside a CSPM rule pack or an EDR dashboard, which is why they've historically lived in one-off scripts and tribal knowledge. Turning them into reusable, continuously evaluated policies is the point.
FAQ
Can a CSPM or CNAPP tell me if CrowdStrike is missing from a workload?
Generally no. CSPM and CNAPP tools evaluate cloud configuration and posture (misconfigurations, permissions, exposure) rather than verifying that a specific third-party endpoint agent is installed and running inside each workload. Some can report on their own native runtime sensor's coverage, which is a different question from your EDR's coverage.
Why can't CrowdStrike itself report every workload that's missing the sensor?
Falcon can show inactive, stale, or reduced-functionality sensors on hosts it knows about. But it has limited visibility into hosts where the sensor was never deployed, because those assets don't report in. Accurate gap detection requires comparing agent status against an independent, complete inventory of every workload, which lives in the cloud control plane rather than in the agent.
What actually counts as an EDR coverage gap?
Three things, not just one: a workload with no agent at all, an agent that's installed but inactive or not checking in, and an agent that's running but out of date or in a degraded/reduced-functionality state. A real coverage policy checks for all three.
How often should coverage be checked?
Continuously. Point-in-time checks drift out of date as soon as new infrastructure is deployed, which is constantly in cloud environments. The goal is to catch a missing agent when the workload launches, not when it shows up in an incident or an audit finding.
imPAC turns infrastructure questions like this into policies your team can build, run, and prove across AWS, Azure, and GCP, in minutes rather than weeks. Request a walkthrough and bring your hardest "we can't prove this" question.